Uber數據基礎架構 現狀與未來數據處理服務展望
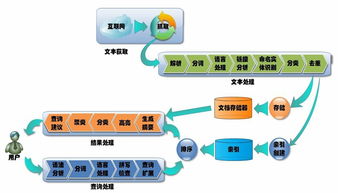
Uber作為全球領先的出行和配送平臺,其數據基礎架構承載著海量實時和歷史數據的處理需求。當前,Uber的數據基礎架構以可擴展性、可靠性和實時性為核心,支撐著從行程匹配到動態定價、安全監控等關鍵業務。數據處理服務已形成完整的生態系統,包括數據采集、存儲、計算和分析等環節。
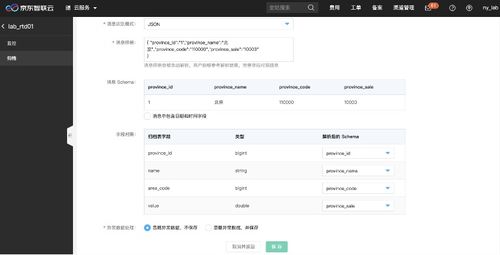
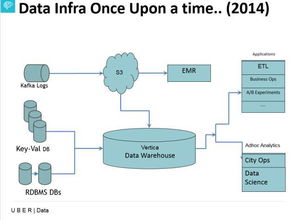
在現狀方面,Uber依賴Apache Kafka進行實時數據流處理,使用Hadoop和Spark進行批處理分析,并采用Presto和Apache Flink支持交互式查詢與復雜事件處理。其自研的 Michelangelo 機器學習平臺整合了數據處理流程,助力模型訓練與部署。數據存儲層則結合了OLAP和OLTP系統,如MySQL、Cassandra和列式存儲,確保數據的高效訪問。
面向未來,Uber數據基礎架構將朝著更智能、自動化和云原生方向發展。數據處理服務將進一步集成AI和ML能力,實現預測性維護和動態資源優化,以降低運營成本。隨著邊緣計算的興起,Uber將加強實時數據處理在本地設備端的部署,提升低延遲響應能力,尤其在自動駕駛和物聯網場景中。數據治理和隱私保護將成為重點,通過加密技術和合規框架確保用戶數據安全。
另一個關鍵趨勢是多云和混合云策略的深化,Uber計劃利用云服務(如AWS、GCP)的彈性,結合自建數據中心,實現資源無縫擴展。同時,流批一體架構將更普及,減少數據冗余并提升處理效率。未來,Uber還可能探索量子計算在優化算法中的應用,以解決超大規模數據挑戰。
Uber的數據基礎架構正從傳統的大數據處理向智能化、實時化和安全化演進,未來數據處理服務將更加聚焦于自動化決策、用戶體驗優化和可持續發展,為全球業務提供堅實支撐。
如若轉載,請注明出處:http://www.t18999.cn/product/8.html
更新時間:2026-01-08 12:41:16