微服務鏈路追蹤 SkyWalking 數據處理服務的原理與實踐
在當今微服務架構日益普及的背景下,系統復雜性不斷攀升,服務間的調用鏈路變得錯綜復雜。為了有效監控和診斷分布式系統中的性能瓶頸與故障,鏈路追蹤技術應運而生。Apache SkyWalking 作為一款優秀的應用性能監控(APM)和鏈路追蹤系統,其數據處理服務扮演著核心角色,負責接收、處理、存儲和分析來自微服務集群的海量追蹤數據。
一、SkyWalking 數據處理服務的核心架構
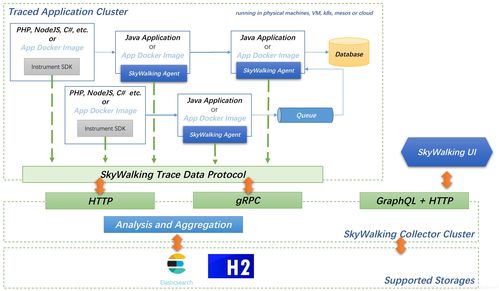
SkyWalking 的數據處理服務主要由兩部分構成:接收器(Receiver)和分析器(Analyzer)。接收器負責從各類探針(如 Java、.NET、Go 等語言的 Agent)或服務網格(如 Istio)收集遙測數據,包括追蹤(Traces)、指標(Metrics)和日志(Logs)。這些數據通常通過 gRPC 或 HTTP 協議傳輸,并支持多種格式,如 SkyWalking 原生協議、Zipkin、Jaeger 和 OpenTelemetry 格式。接收器在獲取數據后,會進行初步的驗證與格式化,確保數據的完整性與一致性。
數據被傳遞到分析器模塊。分析器是數據處理的大腦,它通過一系列可配置的規則和算法,對原始數據進行聚合、計算和關聯。例如,分析器可以將單個請求的細粒度追蹤信息聚合成服務級別的性能指標(如平均響應時間、錯誤率),識別出慢查詢或異常端點,并構建服務依賴拓撲圖。這一過程極大地減少了存儲壓力,同時提煉出對運維和開發人員更具洞察力的信息。
二、數據處理流程詳解
數據處理服務遵循高效、可擴展的流水線設計。原始數據被攝入后,會經過一個實時流處理引擎(默認基于 Apache SkyWalking 自研的 OAP 流處理引擎,也支持集成 Flink 等外部系統)。在此階段,數據會根據預定義的采樣規則進行過濾,以避免數據爆炸;關鍵的業務字段(如 Trace ID、Service ID、Endpoint 名稱)會被提取和標準化,便于后續的索引與查詢。
數據進入聚合階段。SkyWalking 采用時間窗口(如分鐘級)對指標進行滾動計算,例如統計某服務在最近一分鐘內的調用次數和延遲分布。對于追蹤數據,分析器會執行深度分析,識別出分布式事務中的關鍵路徑(Critical Path),并標記出可能存在的性能瓶頸點(如數據庫慢查詢或外部 API 超時)。所有處理結果最終被持久化到存儲后端,SkyWalking 支持多種存儲選項,包括 Elasticsearch、MySQL、TiDB 和 H2(用于測試)。
三、性能優化與可擴展性
面對高并發的微服務環境,SkyWalking 數據處理服務設計了多重優化機制。通過水平擴展 OAP 服務器節點,可以實現負載均衡與高可用性;數據分片策略允許將不同服務或時間段的數據分布到不同的處理單元,提升并行處理能力。內存中的緩存機制(如使用 Caffeine 緩存)減少了頻繁的磁盤 I/O 和網絡開銷,加速了實時查詢響應。
對于超大規模集群,用戶還可以啟用集群管理模式,將接收器與分析器解耦部署,甚至將計算密集型任務卸載到 Flink 等流處理平臺,從而實現彈性伸縮。SkyWalking 的模塊化架構使得這些定制化成為可能,而無需重寫核心邏輯。
四、實踐應用與最佳實踐
在實際部署中,合理配置數據處理服務至關重要。建議根據業務流量調整采樣率(如 100% 采樣用于調試,生產環境可降至 10%-30%),以平衡數據詳盡度與系統開銷。應密切監控 OAP 服務器的資源使用情況(如 CPU、內存和 GC 行為),并依據存儲后端的性能(如 Elasticsearch 的分片與索引策略)進行調優。
集成方面,SkyWalking 與 Kubernetes、Spring Cloud、Dubbo 等生態無縫銜接,通過自動化探針注入和標簽傳播,能夠實現端到端的透明追蹤。結合其強大的可視化儀表盤,團隊可以快速定位故障根因,優化服務性能,提升系統可靠性。
五、未來展望
隨著云原生技術的演進,SkyWalking 數據處理服務也在持續進化。對 eBPF 和無侵入探針的支持,使得監控范圍擴展至更底層的基礎設施;與 OpenTelemetry 標準的深度融合,進一步增強了跨平臺兼容性。我們期待看到更多 AIOps 能力的集成,如基于機器學習自動異常檢測與根因分析,讓數據處理服務不僅止于追溯,更能主動預警與自愈。
SkyWalking 的數據處理服務是微服務可觀測性體系的基石,它通過高效、靈活的數據管道,將原始的分布式追蹤數據轉化為 actionable insights,助力企業在復雜系統中保持清晰視野與穩定運行。
如若轉載,請注明出處:http://www.t18999.cn/product/53.html
更新時間:2026-01-06 08:10:49